Pour ceux qui comme moi aiment bien bosser sur des vieux coucous retapés, on peut parfois se retrouver, sans l’avoir anticiper, sur une interface qui ralentit – qui rame – à mort. La solution radicale : un reboot.
Oui sauf que moi, le reboot de la machine pendant que je travaille, ça ne me va pas tout le temps ! Je vous propose quelques solutions pour sortir de la galère :
Lorsque votre ordinateur sous Debian gèle à cause d’une saturation mémoire, voici les étapes pour tenter de reprendre la main :
1. Accéder à une console virtuelle
Utilisez les touches Ctrl + Alt + F1 (ou F2 à F6) pour accéder à une console virtuelle (TTY). Cela devrait vous permettre de vous connecter avec votre compte utilisateur ou en tant que root.
2. Identifier et tuer les processus gourmands
Une fois connecté, utilisez la commande suivante pour voir quels processus consomment le plus de mémoire : top Ou, pour un affichage plus clair : htop (Si htop n’est pas installé, utilisez apt install htop plus tard.)
Recherchez les processus qui consomment énormément de mémoire (colonne %MEM). Notez leur PID (identifiant de processus) et utilisez : kill -9 PID Remplacez PID par l’identifiant du processus.
3. Libérer la mémoire cache
Si le système est encore réactif, vous pouvez tenter de libérer de la mémoire cache avec cette commande (en root) : echo 3 > /proc/sys/vm/drop_caches
4. Tuer tous les processus utilisateur (si nécessaire)
Si vous êtes root, vous pouvez tuer tous les processus utilisateur (sauf root) : pkill -u username Remplacez username par votre nom d’utilisateur.
5. Redémarrer le gestionnaire graphique
Si votre système utilise un environnement graphique et que celui-ci est gelé, redémarrez-le avec : systemctl restart gdm3 # Pour GNOME systemctl restart sddm # Pour KDE systemctl restart lightdm # Pour d'autres environnements
6. Dernier recours : redémarrer les processus liés à l’interface graphique
Si aucune de ces solutions ne fonctionne, vous pouvez tenter cette astuce (qui fonctionne souvent du 1er coup)
Maintenez Alt + SysRq (la touche « Print Screen ») + K ; votre session devrait redémarrer en tuant tous les process. Radical mais efficace.
Prévention pour l’avenir
Augmenter le swap : Si votre swap est insuffisant, augmentez-le en suivant ces instructions.
Surveiller la mémoire : Configurez des outils comme earlyoom ou systemd-oomd pour tuer automatiquement les processus en cas de saturation.
Vous pouvez personnaliser les règles SELinux en fonction de vos besoins spécifiques. Utilisez les outils comme semanage et setsebool pour ajuster les politiques SELinux.
Exemple d’ajustement des règles pour un service spécifique (par exemple, HTTPD) :
setsebool -P httpd_can_network_connect on
7. (optionnel) configurer les règles de SELinux :
Si vous rencontrez des problèmes avec SELinux, utilisez audit2allow pour analyser et générer des règles permettant de corriger les problèmes.
Par exemple, pour analyser les erreurs et générer une politique d’autorisation :
SELinux utilise des contextes pour contrôler l’accès aux fichiers et aux répertoires. Nginx nécessite des contextes spécifiques pour fonctionner correctement.
Vérifier les contextes actuels des fichiers de Nginx :
ls -Z /etc/nginx
ls -Z /usr/share/nginx/html
Appliquer les contextes SELinux nécessaires
Appliquer le contexte correct aux répertoires et fichiers Nginx :
semanage fcontext -a -t httpd_sys_content_t "/usr/share/nginx/html(/.*)?"
restorecon -Rv /usr/share/nginx/html
semanage fcontext -a -t httpd_sys_content_t "/etc/nginx(/.*)?"
restorecon -Rv /etc/nginx
Permettre à Nginx d’écouter sur le réseau :
setsebool -P httpd_can_network_connect 1
6. Vérifier le bon fonctionnement de Nginx :
Accédez à l’adresse IP de votre serveur depuis un navigateur web pour vérifier que Nginx fonctionne correctement. Vous devriez voir la page d’accueil par défaut de CENTOS :
7. Dépannage et gestion des erreurs
Si vous rencontrez des erreurs, vous pouvez utiliser audit2allow pour créer des règles SELinux qui permettent les opérations nécessaires à Nginx.
Exemple d’utilisation d’audit2allow :
1. Reproduisez l’erreur.
2. Vérifiez les logs SELinux pour trouver les erreurs associées à Nginx :
grep nginx /var/log/audit/audit.log
3. Utilisez audit2allow pour générer et appliquer une nouvelle politique :
En suivant ces étapes, vous pouvez installer et configurer Nginx sur une machine avec SELinux en mode enforcing. La clé est de s’assurer que les contextes SELinux sont correctement définis pour permettre à Nginx de fonctionner sans restriction.
On va pouvoir maintenant passer à l’ajout de PHP.
3. Installer PHP sur Centos avec NGinx et SELinux
Pour installer PHP sur une machine CentOS avec Nginx, suivez ces étapes :
1. Installer EPEL et Remi Repository
Les paquets PHP les plus récents sont souvent disponibles dans le dépôt Remi. Commencez par installer EPEL (Extra Packages for Enterprise Linux) et le dépôt Remi.
Redémarrez Nginx pour appliquer les modifications :
sudo systemctl restart nginx
8. Tester l’installation de PHP
Créez un fichier PHP de test pour vous assurer que PHP fonctionne correctement avec Nginx. Par exemple :
sudo nano /usr/share/nginx/html/info.php
Ajoutez le contenu suivant :
<?php
phpinfo();
?>
Accédez à ce fichier via votre navigateur web en visitant http://your_server_ip/info.php. Vous devriez voir la page d’information PHP, indiquant que PHP fonctionne correctement avec Nginx.
Le mot de la fin
Et voilà, cette procédure vous permet à priori d’avoir un serveur PHP tournant sous SELinux prêt à l’emploi ! Je ne suis pas entré volontairement dans les détails sur certains points qui paraissent un peu obscurs mais je ne manquerai pas d’y revenir un peu plus tard 😉
On voit souvent l’affirmation selon laquelle une fonction ou un algorithme de hashage permte d’assurer l’intégrité des données. Concrètement, pourquoi et comment ça marche ? C’est ce qu’on va tenter de comprendre simplement ici.
Qu’est-ce qu’un algorithme de hashage ?
Un algorithme de hashage prend une entrée (ou message) et produit une sortie de taille fixe appelée « haché » ou « digest ». Cette sortie est généralement une séquence de bits ou de caractères. Les algorithmes de hashage couramment utilisés incluent MD5, SHA-1, et les membres de la famille SHA-2 (comme SHA-256).
Caractéristiques des fonctions de hachage cryptographiques
Déterminisme :
Une fonction de hachage est déterministe, ce qui signifie que le même message d’entrée produira toujours le même haché. Cela permet de vérifier la consistance des données.
Rapidité :
Les fonctions de hachage sont conçues pour être rapides à calculer, ce qui les rend pratiques pour une utilisation fréquente.
Préimage résistante :
Il est computationnellement difficile de retrouver le message original à partir de son haché, ce qui protège les données contre certaines formes d’attaques.
Résistance aux collisions :
Il est difficile de trouver deux messages distincts qui produisent le même haché. Cela assure que chaque message a un haché unique, renforçant ainsi l’intégrité des données.
Avalanche effect :
Une petite modification de l’entrée (même un seul bit) entraîne un changement radical et imprévisible du haché. Cela permet de détecter même les plus petites altérations dans les données.
Assurance de l’intégrité des données
L’intégrité des données signifie que les données n’ont pas été altérées ou corrompues. Voici comment les fonctions de hachage contribuent à cette assurance :
Vérification de l’intégrité :
Lorsque des données sont envoyées ou stockées, leur haché est souvent calculé et transmis ou stocké avec elles. Plus tard, pour vérifier que les données n’ont pas été modifiées, le haché des données reçues ou récupérées est recalculé et comparé au haché original. Si les deux hachés correspondent, les données sont considérées comme intactes.
Détection de la corruption :
Si les données sont altérées de quelque manière que ce soit, même légèrement, le haché recalculé sera différent du haché original, signalant que l’intégrité des données a été compromise.
Exemple pratique
Prenons un exemple concret pour illustrer :
Calcul initial du haché :
Supposons que vous avez un fichier appelé document.txt. Vous calculez son haché en utilisant un algorithme de hachage comme SHA-256 :
sha256sum document.txt
Le résultat pourrait être quelque chose comme 3a7bd3e2360a3e756b81d7ba7e65a7ff.
Transmission et stockage :
Vous envoyez document.txt à un collègue et incluez le haché 3a7bd3e2360a3e756b81d7ba7e65a7ff.
Vérification de l’intégrité :
Votre collègue reçoit document.txt et recalcule son haché en utilisant la même commande :
sha256sum document.txt
Si le haché recalculé correspond à 3a7bd3e2360a3e756b81d7ba7e65a7ff, cela signifie que le fichier n’a pas été modifié pendant la transmission.
En bref
Les algorithmes de hachage assurent l’intégrité des données en fournissant un moyen simple et efficace de vérifier que les données n’ont pas été altérées. Grâce aux caractéristiques uniques des fonctions de hachage, telles que la résistance aux collisions et l’effet avalanche, même les plus petites modifications des données peuvent être détectées, garantissant ainsi que les données restent intactes et fiables.
foreach ($item in $collection) {
# Actions à effectuer
}
Condition If :
if ($condition) {
# Actions si condition est vraie
} elseif ($autre_condition) {
# Actions si autre condition est vraie
} else {
# Actions si aucune condition n'est vraie
}
Installer Proxmox VE (Virtual Environment) sur une machine dédiée est une excellente façon de mettre en place un environnement de virtualisation robuste chez vous. Voici les étapes détaillées pour installer Proxmox VE sur un serveur ou PC dédié.
Prérequis
Hardware Compatible: Assurez-vous que votre machine répond aux exigences minimales de Proxmox VE :
CPU 64 bits avec support de virtualisation (Intel VT ou AMD-V)
Au minimum 2 Go de RAM (8 Go recommandés pour une utilisation plus confortable)
Disque dur avec au moins 16 Go d’espace disponible
Carte réseau Ethernet
Téléchargement de l’image ISO de Proxmox VE: Rendez-vous sur le site officiel de Proxmox pour télécharger la dernière version de Proxmox VE sous forme d’image ISO. (https://www.proxmox.com/en/downloads)
Création d’un support d’installation USB: Utilisez un outil tel que Rufus (https://rufus.ie/en/) pour créer une clé USB bootable à partir de l’image ISO téléchargée.
Installation
Configurer le BIOS/UEFI :
Démarrez votre machine et accédez au BIOS/UEFI.
Modifiez l’ordre de démarrage pour démarrer en premier lieu à partir de la clé USB.
Assurez-vous que les options de virtualisation (Intel VT-x ou AMD-V) sont activées.
Démarrer depuis la clé USB :
Insérez la clé USB bootable et redémarrez votre machine.
Sélectionnez l’option pour démarrer à partir de la clé USB.
Installation de Proxmox VE :
Suivez les instructions à l’écran pour commencer l’installation.
Acceptez les conditions d’utilisation.
Sélectionnez votre disque dur pour l’installation de Proxmox.
Configurez votre adresse réseau (il est recommandé de configurer une IP statique).
Définissez un mot de passe pour l’utilisateur root et saisissez votre adresse email pour les alertes système.
Lancez l’installation.
Redémarrage et première connexion :
Une fois l’installation terminée, retirez la clé USB et redémarrez le système.
Accédez à l’interface web de Proxmox VE en entrant l’adresse IP de votre serveur dans un navigateur web suivi de :8006 (exemple : https://192.168.1.100:8006).
Connectez-vous en utilisant le nom d’utilisateur root et le mot de passe que vous avez configuré.
Configuration post-installation
Mise à jour du système : Connectez-vous à Proxmox VE et vérifiez les mises à jour système disponibles via l’interface web.
Créer des VMs ou des conteneurs : Commencez à créer des machines virtuelles ou des conteneurs LXC via l’interface de Proxmox.
Sécurisation de votre installation
Changez les mots de passe par défaut et utilisez des mots de passe forts.
Configurez un pare-feu sur votre Proxmox VE ou en périphérie de votre réseau.
Mettez en place des backups réguliers de vos VMs et conteneurs pour éviter des pertes de données.
Lorsque vous téléchargez des fichiers et/ou des exécutables sur diverses sources, vous avez très probablement déjà rencontré des lignes « checksum » qui donnent un hash comme information. A quoi ça sert concrètement ?
Principe de fonctionnement du checksum
Les checksums ou sommes de contrôle (hash) sont utilisés pour s’assurer de l’intégrité des fichiers téléchargés. Ils permettent de vérifier que le fichier que vous avez téléchargé est exactement celui que l’auteur a mis à disposition et qu’il n’a pas été altéré ou endommagé pendant le processus de téléchargement.
Cela est particulièrement important pour les fichiers exécutables, car une altération peut signifier la présence de logiciels malveillants.
Pour vérifier un checksum, vous pouvez suivre ces étapes générales :
Téléchargez le fichier que vous souhaitez vérifier.
Localisez le checksum fourni par l’auteur sur le site où vous avez téléchargé le fichier. Cela peut être directement à côté du lien de téléchargement ou sur une page dédiée aux checksums.
Utilisez un outil de vérification de checksum pour calculer le checksum du fichier que vous avez téléchargé. Voici comment vous pouvez le faire selon votre système d’exploitation :
Sur Windows :
Vous pouvez utiliser une application comme HashCheck ou 7-Zip pour vérifier les checksums. 7-Zip, par exemple, offre une option dans le menu contextuel pour calculer le hash d’un fichier.
Alternativement, vous pouvez utiliser PowerShell
Get-FileHash C:\chemin\vers\votre\fichier -Algorithm SHA256(Remplacez SHA256 par l’algorithme utilisé pour le checksum, tel que MD5 ou SHA1, si nécessaire)
Sur macOS :
Ouvrez le Terminal et utilisez la commande suivante shasum -a 256 /chemin/vers/le/fichier(Changez 256 en 1 ou 512 selon l’algorithme utilisé – SHA1, SHA256, etc.).
Sur Linux :
Dans un terminal, utilisez une commande similaire à celle de macOS. Par exemple sha256sum /chemin/vers/le/fichierAdaptez la commande à l’algorithme utilisé (par exemple md5sum pour MD5).
Comparez le checksum calculé avec celui fourni sur le site web. Si les deux checksums correspondent, votre fichier est conforme à l’original. Si ce n’est pas le cas, il peut être corrompu ou altéré.
Comment créer un checksum pour les fichiers que je partage ?
Pour créer un checksum pour les fichiers que vous souhaitez partager, vous pouvez utiliser différents outils et méthodes selon votre système d’exploitation. Voici comment procéder sous Windows, macOS et Linux :
Sur Windows
Utiliser PowerShell :
Ouvrez PowerShell en recherchant « PowerShell » dans le menu démarrer.
Utilisez la commande suivante pour créer un checksum SHA256 pour votre fichier : Get-FileHash -Path "C:\chemin\vers\le\fichier" -Algorithm SHA256
Vous pouvez remplacer SHA256 par un autre algorithme tel que MD5, SHA1, SHA384, ou SHA512 selon vos besoins.
Utiliser des outils tiers :
Des applications comme HashMyFiles ou 7-Zip peuvent également créer des checksums. Avec 7-Zip, vous pouvez cliquer avec le bouton droit sur le fichier, sélectionner 7-Zip, puis « CRC SHA » > « SHA-256 ».
Sur macOS
Utiliser le Terminal :
Ouvrez le Terminal.
Pour créer un checksum SHA256, utilisez la commande suivante : shasum -a 256 /chemin/vers/le/fichier
Remplacez 256 par 1 ou 512 pour utiliser SHA1 ou SHA512.
Sur Linux
Utiliser le Terminal :
Ouvrez un terminal.
Pour générer un checksum SHA256, entrez : sha256sum /chemin/vers/le/fichier
Pour d’autres algorithmes, remplacez sha256sum par md5sum, sha1sum, sha512sum, etc., selon l’algorithme désiré.
Partager le checksum
Après avoir généré le checksum, il est courant de partager le hash généré avec le fichier. Vous pouvez créer un fichier texte contenant le checksum et l’ajouter au téléchargement ou le lister sur la page web où les fichiers sont téléchargés. Assurez-vous que le checksum est facilement accessible et clairement indiqué pour que les utilisateurs puissent le vérifier après avoir téléchargé le fichier.
Préparer un plan réseau en amont est une étape cruciale pour toute organisation souhaitant optimiser ses opérations et garantir une infrastructure IT fiable et sécurisée.
Cette démarche offre une multitude d’avantages, essentiels pour naviguer dans l’environnement technologique complexe et en constante évolution d’aujourd’hui. Voici pourquoi élaborer un plan réseau en amont est non seulement avantageux mais indispensable :
Vision claire et cohérente : Un plan réseau permet d’avoir une vue d’ensemble de l’infrastructure actuelle et future, facilitant l’intégration harmonieuse des technologies et des services. Il aide à anticiper les besoins en matière de connectivité, de performance et de sécurité, évitant ainsi les improvisations de dernière minute.
Optimisation des ressources : En identifiant précisément les besoins en équipements, logiciels et adresses IP, le plan réseau permet de faire des choix stratégiques sur l’acquisition de ressources, évitant le surdimensionnement ou le sous-dimensionnement des capacités réseau, qui peuvent entraîner des coûts supplémentaires ou des performances insuffisantes.
Sécurité renforcée : Une planification détaillée inclut l’évaluation des risques et la mise en place de mesures de sécurité adaptées à chaque segment du réseau. Cela permet de construire une architecture résiliente face aux menaces externes et internes, protégeant ainsi les données critiques de l’entreprise.
Scalabilité et flexibilité : Un plan bien conçu tient compte de la croissance future de l’organisation et de ses besoins évolutifs. Il offre une structure flexible qui peut s’adapter et s’agrandir sans perturbations majeures, assurant ainsi une continuité d’activité et une capacité à intégrer de nouvelles technologies.
Efficacité opérationnelle : En prévoyant les interactions entre les différents composants du réseau, le plan permet d’optimiser le flux de données et d’améliorer la performance générale du système. Cela se traduit par une meilleure expérience utilisateur, une réduction des temps d’arrêt et une augmentation de la productivité.
Support et maintenance facilités : Un plan réseau clair et documenté simplifie la tâche des équipes IT pour le dépannage, les mises à jour et la maintenance préventive. Cela réduit le temps de résolution des problèmes et augmente la fiabilité du réseau.
En somme, la préparation d’un plan réseau en amont est un investissement stratégique qui met en lumière la direction à suivre pour une infrastructure IT solide, sécurisée et évolutive. Elle prépare le terrain pour une gestion efficace des ressources technologiques, essentielle au succès et à la compétitivité de toute entreprise moderne.
La to-do list pour ne rien oublier au démarrage
Pour élaborer un plan d’adressage réseau efficace, suivez les étapes ci-dessous pour cerner précisément vos besoins :
Étape 1 : Analysez les besoins fondamentaux de votre réseau :
Identifiez le total des nœuds au sein de votre réseau. Ceci inclut tous les dispositifs connectés.
Déterminez si ces nœuds requièrent des adresses IP publiques ou privées, selon leur nécessité d’accès externe.
Évaluez la connectivité de vos nœuds : utilisez-vous des dispositifs de couche 2 (liaison), de couche 3 (réseau), ou un mélange des deux ? Si oui, précisez le nombre de nœuds par type de dispositif.
Prenez en compte les adresses IP supplémentaires éventuellement nécessaires pour la gestion. Ces adresses, souvent publiques, peuvent être destinées à l’administration à distance des équipements réseau.
Ajoutez au décompte les adresses IP de gestion nécessaires pour chaque dispositif réseau, sachant qu’elles peuvent être accessibles ou non via Internet.
Étape 2 : Évaluez les besoins relatifs aux connexions WAN (Wide Area Network) :
Estimez le nombre de connexions WAN requises.
Calculez le nombre d’adresses IP nécessaires par connexion WAN.
En absence de fourniture d’adresses IP WAN par votre opérateur, utilisez la formule suivante pour déterminer vos besoins : IPs publiques = nombre de connexions WAN x IPs nécessaires par WAN. Puis, documentez le nombre total d’adresses IP publiques ainsi que leur équivalent en notation CIDR (Classless Inter-Domain Routing).
Étape 3 : Définissez les besoins spécifiques à chaque service :
Comptabilisez le nombre de serveurs par service.
Déterminez le nombre d’adresses IP requis pour chaque serveur.
Identifiez les services nécessitant un accès Internet, ainsi que ceux uniquement disponibles en interne.
Étape 4 : Considérez les exigences de vos utilisateurs finaux :
Pour chaque catégorie d’utilisateurs, évaluez le nombre d’adresses IP nécessaires.
Déterminez si un service exige l’attribution d’adresses IP publiques aux utilisateurs finaux, et le cas échéant, quantifiez ces besoins par utilisateur et par catégorie.
Recensez le nombre d’utilisateurs par catégorie.
Après avoir détaillé les besoins et spécificités de votre réseau, récapitulez les informations collectées dans un tableau. Ce document servira de base pour votre planification et pourra être intégré à la documentation technique de votre projet.
Un exemple concret : le point de vue « macro » :
Imaginons un plan d’adressage réseau qui couvre différents services essentiels d’une PME de trente employés qui fabrique des crayons.
Le tableau ci-dessous peut illustrer un exemple « global » de configuration réseau adaptée à de telles nécessités, en tenant compte de l’infrastructure réseau, des serveurs, des postes de travail des employés, et d’autres dispositifs nécessaires à l’activité de l’entreprise.
Service
Plage d’adresses IP
Masque de sous-réseau
Passerelle par défaut
Réseau administratif
192.168.1.0 – 192.168.1.63
255.255.255.192
192.168.1.1
Réseau de production
192.168.1.64 – 192.168.1.127
255.255.255.192
192.168.1.65
Serveurs (DHCP, File, Print)
192.168.1.128 – 192.168.1.191
255.255.255.192
192.168.1.129
Wi-Fi Employés
192.168.1.192 – 192.168.1.255
255.255.255.192
192.168.1.193
Détails du plan d’adressage :
Réseau administratif : Ce segment est destiné aux ordinateurs et périphériques utilisés par l’administration. Il supporte jusqu’à 62 appareils.
Réseau de production : Ce segment regroupe les machines de contrôle et les terminaux utilisés directement dans le processus de fabrication. Il est conçu pour accueillir jusqu’à 62 appareils spécifiques à la production.
Serveurs : Une plage réservée aux serveurs essentiels tels que DHCP (pour la distribution automatique des adresses IP), de fichiers (pour le stockage partagé) et d’impression. Cette plage peut supporter jusqu’à 62 serveurs ou dispositifs de réseau.
Wi-Fi Employés : Segment dédié à l’accès Internet sans fil pour les employés. Il offre la connectivité à jusqu’à 62 dispositifs.
Chaque segment de réseau est configuré avec son propre masque de sous-réseau pour optimiser l’utilisation des adresses IP et est délimité par une passerelle spécifique, facilitant ainsi la gestion du trafic et l’accès à Internet.
Ce plan est conçu pour être évolutif, permettant à l’entreprise de grandir ou de restructurer ses services sans nécessiter une refonte complète du réseau. De plus, il assure une séparation logique des différentes fonctions de l’entreprise, ce qui renforce la sécurité et l’efficacité du réseau.
Et une version « micro » qui permet de détailler les postes
Pour approfondir l’exemple précédent et illustrer comment les postes spécifiques pourraient être assignés au sein d’une PME fabricant des crayons, nous allons détailler la répartition des adresses IP pour certains rôles clés dans l’entreprise. Cela inclura la direction, le département de production, les services informatiques, et l’accès Wi-Fi pour les employés.
Service
Adresse IP
Masque de sous-réseau
Passerelle par défaut
Description du poste
Réseau administratif
192.168.1.2
255.255.255.192
192.168.1.1
Ordinateur du Directeur
Réseau administratif
192.168.1.3
255.255.255.192
192.168.1.1
Poste de travail de la Comptabilité
Réseau administratif
192.168.1.4
255.255.255.192
192.168.1.1
Poste de travail des Ressources Humaines
Réseau de production
192.168.1.66
255.255.255.192
192.168.1.65
Terminal de gestion de ligne de production
Réseau de production
192.168.1.67
255.255.255.192
192.168.1.65
PC de l’ingénieur de production
Serveurs
192.168.1.130
255.255.255.192
192.168.1.129
Serveur DHCP
Serveurs
192.168.1.131
255.255.255.192
192.168.1.129
Serveur de fichiers
Wi-Fi Employés
192.168.1.194
255.255.255.192
192.168.1.193
Connexion pour tablette d’un employé
Détails des rôles et configurations :
Ordinateur du Directeur (192.168.1.2): Cet appareil est utilisé pour les opérations administratives de haut niveau, y compris la prise de décision stratégique.
Poste de travail de la Comptabilité (192.168.1.3): Utilisé pour la gestion financière, les paiements et la facturation.
Poste de travail des Ressources Humaines (192.168.1.4): Sert pour la gestion du personnel, le recrutement et les dossiers des employés.
Terminal de gestion de ligne de production (192.168.1.66): Permet de contrôler les machines de fabrication et de suivre la production en temps réel.
PC de l’ingénieur de production (192.168.1.67): Utilisé pour la conception des produits, la maintenance des équipements et l’optimisation des processus de production.
Serveur DHCP (192.168.1.130): Attribue automatiquement des adresses IP aux dispositifs connectés au réseau pour faciliter leur configuration et gestion.
Serveur de fichiers (192.168.1.131): Centralise le stockage des fichiers importants de l’entreprise, facilitant l’accès et le partage sécurisé des données.
Connexion pour tablette d’un employé (192.168.1.194): Offre un accès Wi-Fi sécurisé pour les employés souhaitant se connecter au réseau de l’entreprise via des dispositifs personnels ou professionnels mobiles.
Cette configuration démontre comment un plan d’adressage réseau peut être personnalisé pour répondre aux besoins spécifiques de chaque rôle au sein de l’entreprise, tout en assurant la sécurité, l’efficacité et la scalabilité du réseau.
Dans le monde des affaires d’aujourd’hui, où la technologie joue un rôle crucial dans presque tous les aspects de l’entreprise, avoir une compréhension claire et précise de l’infrastructure technologique est indispensable. C’est ici que le Document d’Architecture Technique (DAT) entre en jeu, un outil essentiel pour garantir que tous les aspects techniques d’une entreprise sont non seulement bien conçus mais aussi correctement alignés avec les objectifs commerciaux. Dans cet article, nous explorerons la nécessité et l’utilité de rédiger un DAT dans une entreprise.
1. Définition du DAT
Un Document d’Architecture Technique est un document qui décrit de manière détaillée la structure technique d’un projet informatique. Il couvre l’ensemble des choix techniques, des logiciels utilisés, de l’infrastructure réseau, des protocoles de communication, ainsi que des normes de sécurité à appliquer. Ce document sert de référence tout au long du cycle de vie du projet, de la conception à la maintenance, en passant par la mise en œuvre.
2. Nécessité du DAT
La rédaction d’un DAT n’est pas un luxe mais une nécessité pour plusieurs raisons :
Alignement des objectifs : Il assure que les solutions techniques proposées sont en accord avec les objectifs commerciaux de l’entreprise.
Communication claire : Il sert de document de référence pour tous les intervenants du projet, facilitant ainsi la communication entre les équipes techniques et non techniques.
Prise de décision éclairée : En documentant les choix techniques, le DAT aide les décideurs à comprendre les implications de ces choix sur le long terme.
Gestion des risques : Il permet d’identifier et de gérer les risques techniques dès les premières phases du projet.
3. Utilité du DAT
L’utilité d’un DAT est multiple :
Documentation de référence : Il fournit une vue d’ensemble et détaillée de l’architecture technique, utile pour la formation des nouvelles recrues et pour la maintenance.
Cohérence et standardisation : Il aide à maintenir la cohérence et la standardisation des pratiques techniques au sein de l’entreprise.
Facilitation des mises à jour et des évolutions : Grâce au DAT, comprendre l’architecture existante et y apporter des modifications devient plus aisé.
Optimisation des ressources : En identifiant clairement les besoins en matériel et en logiciels, le DAT permet une meilleure allocation des ressources.
La rédaction d’un Document d’Architecture Technique est une étape cruciale dans la gestion de projets informatiques en entreprise. En offrant une compréhension profonde de l’infrastructure technique et en assurant l’alignement entre les objectifs commerciaux et techniques, le DAT devient un outil indispensable pour le succès des projets. Il favorise une meilleure communication, une prise de décision éclairée, et une gestion des risques plus efficace, ce qui, in fine, contribue à la réalisation des objectifs de l’entreprise de manière plus efficiente et effective.
Que doit contenir un DAT concrètement ?
Un Document d’Architecture Technique (DAT) doit être structuré de manière à offrir une vue complète et détaillée de l’architecture technique d’un projet ou d’un système informatique. Voici les éléments clés qui doivent y figurer de manière concrète :
1. Introduction
Objectif du document : Définition claire de la raison d’être du DAT.
Portée du projet : Limites et étendue de l’architecture couverte par le document.
Public cible : Identification des parties prenantes et de leur rôle.
2. Description de l’architecture existante
Contexte actuel : Description de l’environnement technique actuel, si applicable.
Contraintes existantes : Limitations techniques, financières, opérationnelles ou autres.
3. Besoins et exigences
Besoins fonctionnels : Ce que le système doit faire, souvent dérivé des exigences du business.
Exigences non fonctionnelles : Performance, sécurité, fiabilité, etc.
4. Architecture proposée
Vue globale : Schéma général de l’architecture envisagée, montrant comment les différents composants interagissent.
Composants du système : Description détaillée des éléments du système (serveurs, bases de données, réseaux, services cloud, etc.), leur fonction, et la manière dont ils s’intègrent dans l’ensemble.
Technologies utilisées : Langages de programmation, frameworks, protocoles, standards, etc.
5. Sécurité
Stratégies de sécurité : Méthodes utilisées pour protéger le système contre les menaces et les vulnérabilités.
Conformité : Assurer que l’architecture respecte les réglementations et normes de sécurité applicables.
6. Infrastructure réseau
Topologie réseau : Schéma de l’infrastructure réseau, y compris les sous-réseaux, les VLANs, etc.
Connectivité : Description des liaisons réseau, des protocoles de communication, et des politiques de routage.
7. Gestion des données
Modélisation des données : Structure des bases de données, schémas, entités et relations.
Politiques de gestion des données : Backup, rétention, archivage, et récupération en cas de sinistre.
8. Intégration et déploiement
Stratégies d’intégration : Comment les différents composants et systèmes seront intégrés.
Déploiement : Méthodes de déploiement, y compris la description des environnements de développement, de test, de préproduction et de production.
9. Plan de test
Tests techniques : Stratégies et plans pour tester la performance, la sécurité, la compatibilité, etc.
Critères d’acceptation : Normes et indicateurs de succès pour les tests.
10. Gestion du changement et évolutivité
Procédures de mise à jour : Comment les modifications seront gérées au fil du temps.
Évolutivité : Prévisions sur la capacité du système à évoluer en réponse à l’augmentation de la demande.
11. Annexes
Glossaire : Définitions des termes techniques spécifiques.
Références : Documents, normes, ou articles cités.
Chaque DAT est unique et doit être adapté aux spécificités du projet pour lequel il est rédigé. Cela dit, inclure ces éléments fournira une base solide pour documenter de manière exhaustive l’architecture technique d’une entreprise ou d’un projet spécifique.
Récemment, en explorant des alternatives aux protocoles FTP ou SFTP pour le transfert de fichiers, notamment dans des contextes où les restrictions réseau bloquent certains ports sensibles, j’ai découvert un peu par hasard le protocole WebDAV.
Cette découverte s’est avérée être une révélation intéressante, étant donné que WebDAV offre une solution robuste pour le partage et la collaboration sur des documents via le web, tout en fonctionnant sur le port HTTP standard, souvent laissé ouvert même dans des environnements réseau strictement contrôlés.
Ce protocole étend les capacités du HTTP, permettant non seulement de visualiser mais aussi de créer, modifier, et gérer des documents sur un serveur web de manière interactive. Cette caractéristique le rend particulièrement utile pour contourner les restrictions qui peuvent entraver l’utilisation de FTP ou SFTP, tout en offrant des fonctionnalités avancées de collaboration et de gestion de version qui manquent à ces protocoles plus traditionnels.
Petite définition et avantages / inconvénients
Le protocole WebDAV (Web Distributed Authoring and Versioning) est une extension du protocole HTTP (Hypertext Transfer Protocol) qui permet aux utilisateurs de créer, modifier et déplacer des documents sur un serveur web. Initié par le groupe de travail IETF (Internet Engineering Task Force), WebDAV a été conçu pour faciliter la collaboration entre utilisateurs dans l’édition et la gestion de documents stockés sur des serveurs web.
Avantages de WebDAV
Collaboration facilitée: WebDAV permet à plusieurs utilisateurs de travailler sur le même document simultanément, ce qui est particulièrement utile pour les équipes réparties géographiquement.
Gestion des versions: Il supporte la gestion des versions des documents, permettant aux utilisateurs de suivre et de gérer les changements apportés aux documents au fil du temps.
Interopérabilité: Étant basé sur HTTP, WebDAV fonctionne bien avec de nombreux systèmes d’exploitation et applications, ce qui facilite l’intégration dans des environnements hétérogènes.
Accès distant: Les utilisateurs peuvent accéder et modifier des documents sur un serveur WebDAV depuis n’importe où, à condition d’avoir une connexion Internet.
Sécurité: WebDAV peut être sécurisé avec les mêmes mécanismes que ceux utilisés pour sécuriser HTTP, comme SSL/TLS pour le chiffrement.
Inconvénients de WebDAV
Complexité de configuration: La mise en place d’un serveur WebDAV peut être complexe, nécessitant une configuration minutieuse pour assurer la sécurité et la performance.
Problèmes de compatibilité: Bien qu’il vise l’interopérabilité, des problèmes peuvent survenir avec certains clients ou serveurs WebDAV, en particulier avec des versions plus anciennes.
Performance: L’utilisation de WebDAV peut être plus lente par rapport à d’autres protocoles de partage de fichiers, surtout pour les fichiers volumineux, en raison de la surcharge liée à HTTP.
Sécurité: Bien que WebDAV puisse être sécurisé, il peut introduire des vulnérabilités si la configuration du serveur n’est pas correctement sécurisée, notamment en permettant un accès non autorisé aux fichiers.
Consommation de bande passante: Comme WebDAV fonctionne sur HTTP, la synchronisation de gros volumes de données peut consommer une quantité significative de bande passante.
WebDAV est un protocole puissant pour la collaboration et la gestion de documents sur le web, qui offre des avantages significatifs en termes d’accessibilité et de gestion des versions. Cela dit, il requiert une attention particulière lors de la configuration et peut présenter des défis en termes de performance et de sécurité.
Partons du principe que le serveur Debian est déjà prêt ; sur Centreon, ne pas oublier de vérifier que le module « Linux » est bien installé.
Commencer par installer et activer SNMP :
apt-get install snmpd snmp
systemctl enable snmpd
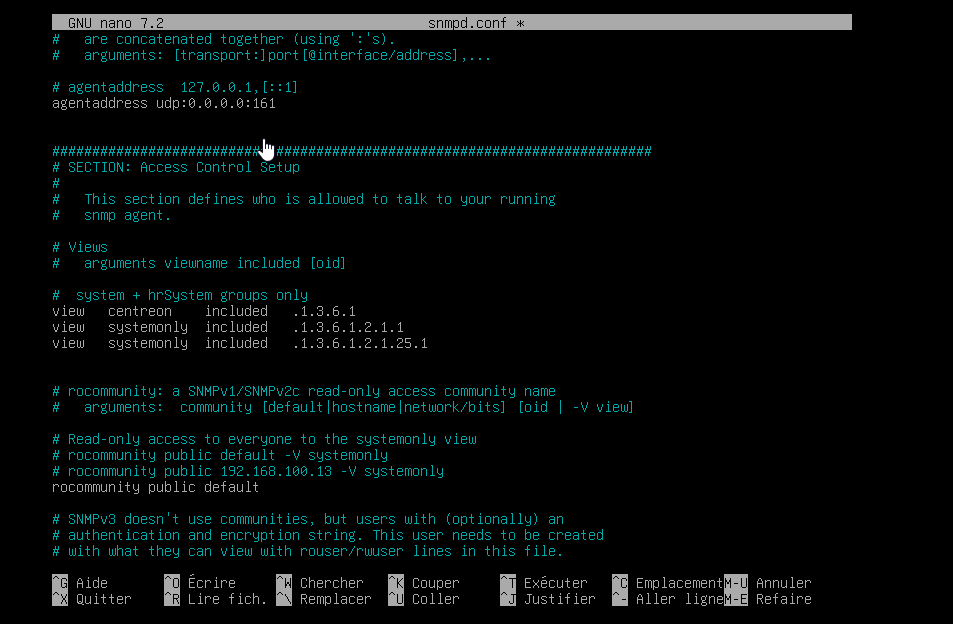
Puis configurer le fichier /etc/snmp/snmpd.conf :
J’ajoute la communauté correspondant à celle enregistrée dans Centreon préalablement “public” pour les tests (bien sûr veiller à changer le nom de la communauté plus tard car trop basique donc peu sécurisé) :
agentAdrress udp:0.0.0.0:161
view centreon included .1.3.6.1
rocommunity public default
Après avoir configuré le nouvel hôte et les services CPU et Mémoire (pour l’exemple), attendre que Centreon rafraîchisse ses infos :